For a long time I thought that Node.js was moving a bit slowly in their async/await adoption. It seemed like a simple thing to do. Just make the callback optional and return a promise if it's not given. In the last weeks I discovered that the Node.js developers have been putting a lot of work into the creating good Promise based APIs.
Using async/await to do asynchronous programming makes code so much more readable. The developers working on Node.js have been doing a great job designing and implementing APIs that work better with promises. Some promise based APIs are a slower then their callback based alternatives. For me though the benefits outweigh the small cost in performance. Your mileage may vary.
promisify
The main mechanism that Node introduced shortly after promises were put into V8 is promisify from the util module. It provides an extensible mechanism for providing promise based versions of Node.js APIs.
const { promisify } = require('util')
const zlib = require('zlib')
const deflate = promisify(zlib.deflate)
const inflate = promisify(zlib.inflate)
// still waiting for that sweet sweet top-level async
const main = async () => {
const importantMessage = Buffer.from('legalize it')
const compressed = await deflate(importantMessage)
const decompressed = await inflate(compressed)
assert(decompressed.toString() === importantMessage)
}
main().catch((err) => { console.error(err); process.exit(1) })Promisify will call the wrapped function with any arguments you give it and slap a callback at the end of it. The callback will then either resolve or reject the Promise based on wether or not it gets an error argument.
It has a two special features though for customizing its behavior. You can specify a different function that should be called when a given function is promisified. Simply be specifying a promisify.custom property on a function. An example of this is timers.setTimeout. The original function doesn't follow the Node.js callback style for compatibility with its DOM counter-part. So it needs a custom implementation.
Streams
What excited me most is Node.js adopting the AsyncIterator in their stream module. There are inter-operability mechanisms for both readable and writable streams with AsyncIterators. This makes them a lot easier to work with.
const main = async () => {
// echo back the given input (note that most systems treat process.stdin as
// line-buffered - press enter after entering something to see the result)
for await (const chunk of process.stdin) {
console.log(chunk.toString('base64'))
}
}This also makes error handling a lot simpler, since the AsyncIterator just rejects when an error occurs in the stream.
Writing to Streams
The pipeline operator has made working with streams a lot easier. It resolves te old error handling issue. Since it cleans up all given streams when one of them fails. It also has very good support for AsyncIterator and can neatly be promisified.
const { promisify } = require('util')
const stream = require('stream')
const pipeline = promisify(stream.pipeline)
const setTimeout = promisify(setTimeout)
const main = async () => {
async function* () {
await setTimeout(100)
yield Buffer.from('some lines\nof text\n')
await setTimeout(200)
yield Bufer.from('some more stuff\n')
}
await pipeline(
myGenerator(),
fs.createWritableStream('./some-file')
)
}Working with Transform Streams
One issue I encountered a few times is that Transform streams are not as easy to use. I used a PassThrough stream to solve this in a consice manner.
const fs = require('fs')
const zlib = require('zlib')
const stream = require('stream')
const { promisify } = require('util')
const pipeline = promisify(stream.pipeline)
const readDeflate = (file) => {
const output = new stream.PassThrough()
pipeline(
fs.createReadStream('my-compressed-file'),
zlib.createInflate(),
output,
// no need to handle errors, since they will be propagated by the
// `output` stream
() => {}
)
return output
}Performance
There is some overhead in AsyncIterators when compared to streams. Since after each item is yielded by an async generator, V8 is scheduling the continuation of the generator in the next micro-tick. This overhead can pile on if your stream throughput is really high.
I've done some basic perfomance testing to confirm that the difference is considerable. Here's the time it takes to consume a stream of 10K items. I ran the test10K times. First with the classic API stream (I called it "sync" since in the example all the code is synchronous when using the classic API). After that I ran it with the async API.
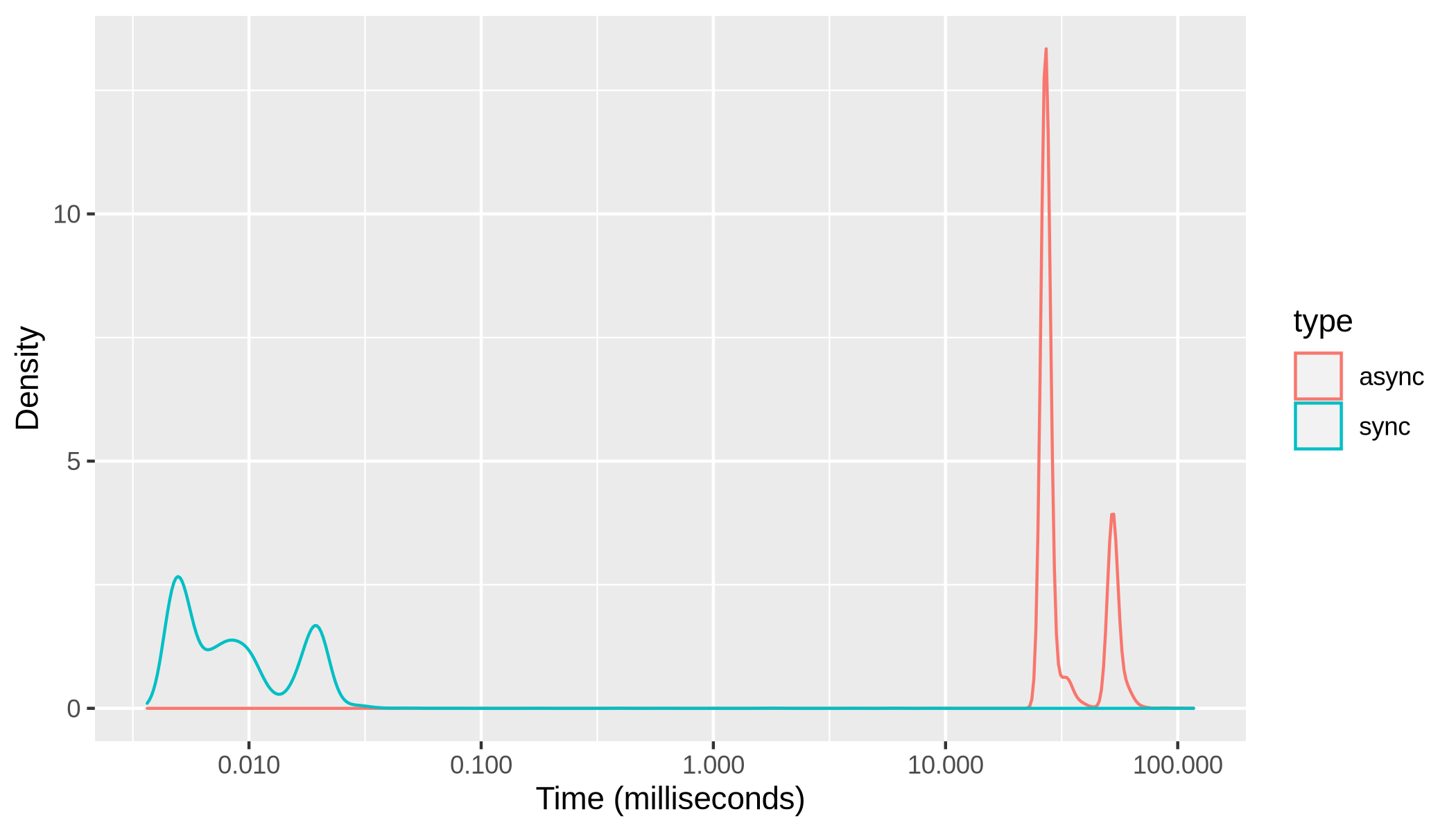
The classic API out-performs the AsyncIterator implementation by 30ms (that's 3500 times longer). Since I'm not doing much work in the Readable stream and because I'm measuring the cost of 1000 iterations, the difference is pretty massive. The example is pretty artificial, it's mainly meant as a word of caution. The callback API is a lot faster. In most cases this difference will be negligible though.
fs
One very nice API to work with is fs.promises. It provides promise based APIs for most things in the main fs module.
const fs = require('fs/promises') // equivalent to `require('fs').promises`
const contents = await fs.readFile('somefile')Example: Splitting Readable streams into lines
async function* readlines (filename) {
let buffer = ''
for await (const chunk of fs.createReadStream(filename)) {
buffer += chunk.toString()
while ((idx = buffer.indexOf('\n')) > -1) {
const line = buffer.substring(0, idx)
buffer = buffer.substring(idx + 1)
yield line
}
}
if (buffer.length) yield buffer
}
const main = async () => {
for await (const line of readlines('./file-name')) {
console.log(line)
}
}In Python it's very ergonomic to read a file line by line. Using async generators we can implement the same thing very easily (and even make it non-blocking).